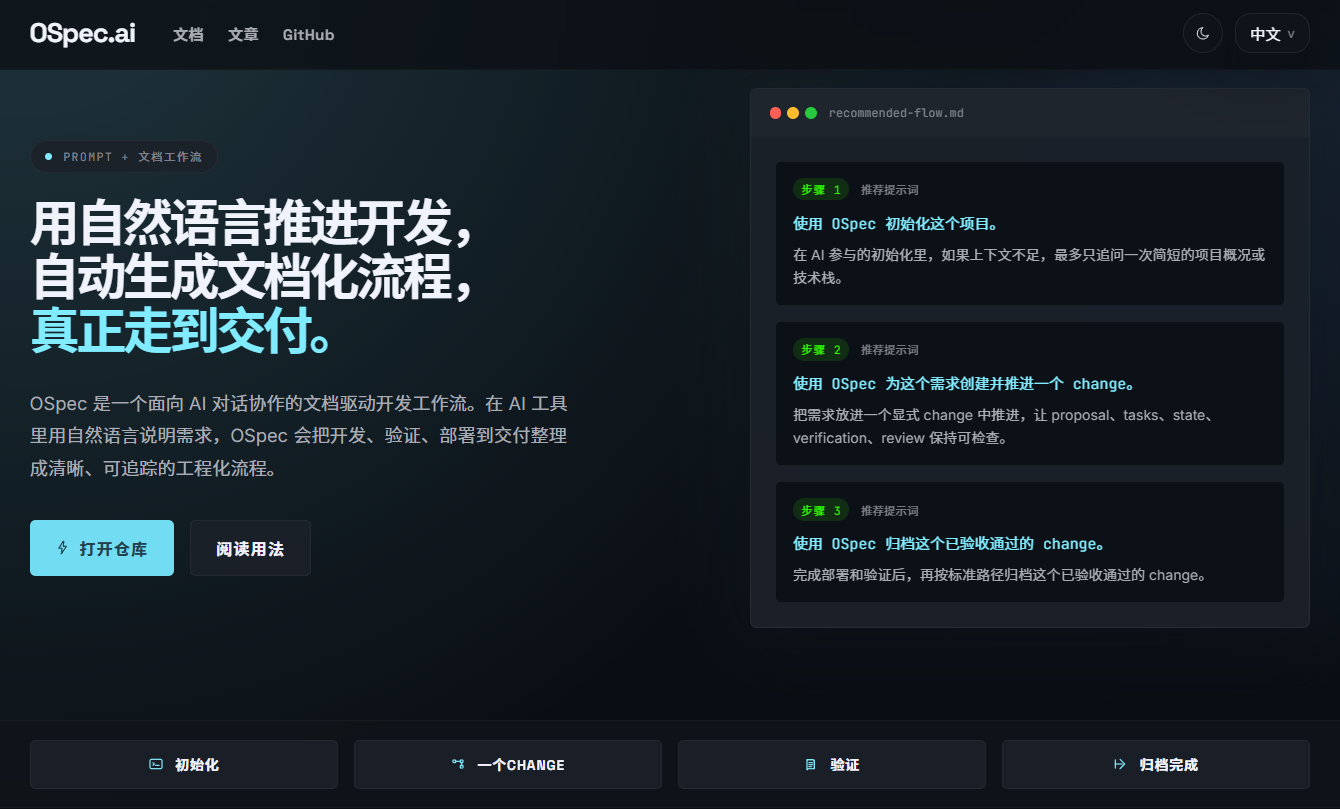
OSpec 如何自动化推进 OSpec.ai 官网开发
很多人第一次看 OSpec,会觉得它只是“给 AI 协作加了一套文档”。
但放到真实项目里,它真正自动化推进的,不只是代码生成,而是整个交付流程。
一句官网需求怎么开始,范围怎么收住,开发怎么推进,验证怎么记录,什么时候上线,最后怎么归档,如果这些事情都只留在聊天里,团队很快就会失去上下文。
这篇文章不讲抽象定义,我直接用 OSpec.ai 官网项目 ospec-web 做例子,讲清楚 OSpec 是怎么把一句需求推进成一个完整 change,并最终走到上线归档的。
先说结论:OSpec 自动化推进的,不只是“写代码”
如果只看表面,OSpec 好像只是多了几个文件和几条命令。
但在 ospec-web 这个项目里,它真正做的事情其实是:
- 先让 AI 读懂项目
- 再把一句需求收进一个 change
- 把范围、任务、状态、验证写进仓库
- 一边开发,一边同步这些文件
- 验证通过后再上线
- 最后把这次 change 归档
所以 OSpec 自动化推进的,不只是“帮你写完页面”,而是“帮你把一个官网需求完整推进到能上线、能回看、能交接”。
用一句话开始,然后进入一个 change
在 ospec-web 里,很多需求的起点并不复杂,往往就是一句话。
比如:
- 做官网首页
- 调整文章系统
- 加一个隐藏后台
- 增加中文文章路由
- 优化某个页面区块
- 补一套 SEO / GEO 字段
当你把这样的需求交给 OSpec 时,它不会直接无边界地开始改代码,而是会先把这件事放进一个独立的 change 里。
这个 change 就是这次工作的主容器。
从 proposal、tasks 到 verification、archive,后面的动作都会围绕它展开。
你可以把它理解成:
从这一步开始,这个需求不再只是聊天记录,而是正式变成仓库里可追踪的一项交付。
在 ospec-web 里,AI 开始前会先读项目
在这个项目里,AI 一般不会凭感觉就开做,而是会先看项目知识层。
最关键的是这些文档:
docs/project/overview.mddocs/project/tech-stack.mddocs/project/architecture.mddocs/project/module-map.md
这些文档分别在告诉 AI:
- 这个项目是干什么的
- 用的是什么技术和部署方式
- 项目整体怎么分层
- 页面、模块、后台、数据库迁移和脚本大概都在哪里
对 ospec-web 来说,这一步非常重要。
因为这个仓库已经不只是一个静态官网,而是一个正在持续演进的内容型站点,里面包括:
- Next.js App Router
- OpenNext for Cloudflare
- Cloudflare Workers 运行时
- 官网页面
- 文章系统
- 隐藏后台
- D1 / R2 相关能力
如果 AI 不先理解这些事实,就很容易把需求做偏。
所以在 OSpec 里,真正的自动化第一步,其实不是写代码,而是先对齐上下文。
一个 change 里,最重要的文件是什么
在 ospec-web 里,一个 active change 通常会带上几份核心文件。
最常见的是这些:
proposal.mdtasks.mdstate.jsonverification.md
很多时候还会有:
review.md
这几个文件加在一起,基本就构成了一个需求从开始到归档的全过程。
proposal.md:先把边界收住
在 ospec-web 里,proposal.md 最像“这次需求到底要做什么”的正式说明。
它通常会写清楚:
- 背景是什么
- 目标是什么
- 会影响哪些模块
- 这次包含什么
- 这次不包含什么
- 验收标准是什么
这一步特别关键,因为官网项目最容易出现的情况就是:
- 改首页,结果顺手把文章系统也带进去
- 改后台,结果又临时加了插件发布
- 本来只想改路由,最后把 SEO、样式、导航、部署一起卷进去
如果没有边界,AI 很容易越做越宽。
而有了 proposal.md,AI 会先把这次 change 的范围写清楚,再继续推进。
所以 proposal.md 的作用不是“多写一份文档”,而是防止整个需求失控。
tasks.md:把需求拆成真的能执行的步骤
如果说 proposal.md 是在回答“做什么”,那 tasks.md 就是在回答“怎么一步一步做”。
在 ospec-web 里,一个 change 往往不是只改一个地方。
它经常会同时碰到:
- 页面
- 内容系统
- 后台
- API
- 路由
- sitemap
- SEO
- 构建
- 部署
所以 AI 会把这次工作拆成一组可执行任务,比如:
- 先确认现有实现
- 再确定影响范围
- 再改页面或后台逻辑
- 再更新配套的 metadata、路由或 sitemap
- 再做构建和 smoke check
- 最后再收口归档
这一步的好处是,团队不会只看到“这个需求还没做完”,而是能知道:
- 已经做到哪一步了
- 还有哪些步骤没做
- 哪些验证已经完成
- 哪些收尾动作还没补
AI 在这一步做的事情,就是把一个模糊目标变成可推进的执行清单。
state.json:让整个流程不只是人能看,系统也能接着走
state.json 是很多人最容易忽略的一份文件,但它对自动化推进很重要。
在 ospec-web 里,它更像 change 的状态面板。
里面通常会记录:
- 当前是不是 active
- 当前处在哪个阶段
- 哪些环节已经完成
- 这次 change 影响了哪些文件
- 最终是不是已经 archived
你可以把它理解成:
proposal.md 和 tasks.md 更偏向人读,state.json 更偏向让工具和 AI 知道“这个 change 现在到底走到哪了”。
AI 在这一步主要负责:
- 随着执行推进更新状态
- 标记 proposal、tasks、verification 是否完成
- 给后面的 verify、archive、finalize 留下清楚的衔接点
所以 state.json 虽然不像正文文档那样好读,但它会让整个 change 跑得更稳。
verification.md:把“做完了”变成“有证据地做完了”
在 ospec-web 里,真正接近上线时,最重要的一份文件往往是 verification.md。
因为这个项目不是改完代码就结束,它还会涉及很多真实验证动作,比如:
npm run build- Cloudflare 相关构建
- 页面访问检查
- 路由是否生效
- sitemap 是否更新
- 后台或 API 是否可用
- 必要时的 smoke check
所以 verification.md 的作用,就是把这些事情记录下来。
这样以后回头看,不会只看到“代码改了”,而是能看到:
- 改完之后做了什么验证
- 哪些结果通过了
- 有没有跳过什么
- 这次 change 凭什么可以上线或归档
在 OSpec 的流程里,这一步非常重要。
因为它把“我觉得差不多好了”变成了“这次确实验证过了”。
review.md:让 change 不只是完成,还更可靠
在 ospec-web 里,如果一个 change 比较大、跨模块、风险高,AI 往往还会留下 review.md。
这份文件不是简单复述做了什么,而是从 review 视角去看:
- 有没有明显问题
- 有没有风险点
- 有没有遗漏的验证
- 有没有值得注意的实现细节
这一步的价值在于:
一个 change 不只是“做完了”,还要尽量“做得可靠”。
尤其官网项目一旦上线,用户看到的是结果,不会关心你中间有没有赶工。
所以 review 这一步,会帮助 AI 和团队一起把问题更早暴露出来。
在 ospec-web 里,代码通常是怎么落下去的
当 proposal 和 tasks 明确后,AI 才会真正开始改代码。
在这个项目里,最常见的修改位置通常是:
src/app/页面与路由处理src/modules/site/官网结构、SEO、多语言、公开页面壳层src/modules/content/文章系统、后台、slug、markdown、媒体上传src/styles/global.css页面样式和文章样式db/migrations/D1 数据迁移docs/API、规划、设计、项目知识文档
这也是为什么 OSpec 很适合 ospec-web 这种项目。
因为真实项目从来不是只改一个文件,而是经常要让页面、后台、数据结构、SEO 和部署动作一起对齐。
AI 在这里做的,不是“随便改一改”,而是围绕 change 已经写明的边界,去持续推进这些模块。
在 ospec-web 里,开发完不等于结束,还要继续验证
在这个项目里,一个 change 真正接近完成,通常至少要经过这些动作:
- 本地开发完成
npm run build通过- 需要时做 Cloudflare 构建验证
- 页面、路由、后台或 API 做 smoke check
- 把结果更新到
verification.md
如果这次需求还涉及明显 UI 变化,甚至还可能要继续走:
- Stitch 设计评审
- Checkpoint 或浏览器流程检查
也就是说,在 OSpec 里,AI 不会停在“代码已经改完”。
它还会继续帮你推进到“这次改动到底有没有被验证”。
这正是自动化推进和普通聊天式开发很不一样的地方。
在 ospec-web 里,怎么上线
ospec-web 当前的主部署方向,是:
- Next.js App Router
- OpenNext
- Cloudflare Workers
项目文档里已经约定了分支和环境关系:
main对应 productiondev对应 staging
所以一次完整 change 的上线,一般会是这样一条路径:
- 本地完成开发
- build 和必要检查通过
- 把验证结果写进
verification.md - 提交代码到对应分支
- 由 GitHub 触发 Cloudflare Workers 构建和部署
- 上线后再做必要的 smoke check
这一步很关键,因为它说明 OSpec 里的“上线”并不是 change 之外的事。
上线本身,就是 change 收口过程的一部分。
为什么上线之后还要 archive
很多人会问,既然已经上线了,为什么还要归档?
因为上线只是“代码到线上了”,归档才表示“这次 change 的记录也完整收口了”。
在 ospec-web 里,一个 change 被 archive 之后,别人以后还能回头看到:
- 当时为什么要做
- 这次 change 范围是什么
- 任务怎么拆的
- 状态怎么推进的
- 最后怎么验证的
- 是怎么走到上线的
这也是 OSpec 和“AI 帮你做完一轮聊天就结束”的最大区别之一。
它会把这次交付留下来,变成仓库里可回看、可交接、可复盘的一部分。
如果把整套流程说得更直白一点
在 ospec-web 这个项目里,OSpec 的自动化推进其实很像下面这样:
- 先让 AI 读懂项目
- 再把一句需求变成一个清楚的 change
- 用
proposal.md收边界 - 用
tasks.md推执行 - 用
state.json记状态 - 用
verification.md留验证依据 - 必要时用
review.md补复核结果 - 本地验证后上线
- 最后 archive 这次 change
所以 AI 在这里做的,不只是“帮你写官网”,而是在陪你把官网需求完整推进到可交付状态。
结语
如果只看命令,OSpec 可能显得很轻。
但放到 OSpec.ai 官网项目 ospec-web 里看,你会发现它真正自动化推进的,其实是整个交付过程。
从一句需求开始,到边界收住、任务拆开、代码落地、验证通过、上线完成,再到最后归档,所有动作都围绕一个 change 持续推进。
这就是为什么在 ospec-web 里,OSpec 不是“附加记录”,而是官网开发过程本身的一部分。
它让团队和 AI 都能更清楚地知道:
- 这次在做什么
- 现在做到哪了
- 有没有验证过
- 是怎么上线的
- 以后怎么回头看这次改动